📍 Generative Model Ⅰ
- Generative model의 경우에는 단순히 만들어 내는것보다 많은 것을 의미한다.
-> Generative(샘플링, 생성, sampling)
-> Density estimation(이상 감지, anolmaly detection)
=> 해당 두가지를 다 할 수 있다면 explicit model이라고 불림
-> unsupervised representation learning(feature learning)
🔥 How can we represent p(x)?
- Bernoulli distribution: (biased) coin flip
-> 하나의 수가 있으면 됨 - 동전 앞면 확률 = p <-> 뒷면 확률 = 1 - p

- Categorical distribution: (biased) m-sided dice
-> 6주사위의 경우 5개의 숫자가 필요(sum = 1)

- 하지만 현실에서 하나의 이미지를 표현하기 위해서도 어마어마하게 많은 parameter가 필요하게 되는데 어떻게 하면 줄일 수 있을까?
-> 만약 모든 변수가 독립적이라면 n개의 파라미터가 필요하게 되는데, 이 경우 원하는 이미지를 생성하거나 보여질 수 없다.
-> 그렇다면 어떻게 해야할까? 중간 정도를 찾아보자!
=> Conditional Independence
-> Chain rule과 Bayes' rule, Conditional independence를 활용하여 만들어 낼 수 있다.


🔥 Auto-regressive model
- 28x28 binary pixels을 가지고 있다고 가정해 목표를 p(x) = p(x1,x2,...,x784)를 학습시키는 것.(x ∈{0,1}^784)
- chain rule을 이용해 표현할 수 있다.

- 순서를 메겨야 한다 - 어떻게 메기는지에 따라 성능, 모델이 달라짐
- i-1까지의 영향을 받는 모델이다.
🔥 NADE: Neural Autoregressive Density Estimator

- i 번째를 앞의 요소에 Dependent하게 만드는 것.
-> Neural Network의 입장에서는 입력값의 차원(Weight)이 계속 달라지게 됨.
- Explicit model: Generate만 하는것이 아니라 확률도 구함.(P(xi | x1:i-1))
- Continuous일 경우, Gaussian의 mixture를 활용하여 해결할 수 있다.
🔥 Pixel RNN
- auto-regressive model로 ordering에 따라 다른 알고리즘을 사용한다.(Row LSTM, Diagonal BiLSTM)

📍 Generative Model Ⅱ
🔥 Variational Auto-Encoder
- VI(Variational Inference): 목표는 Posterior deistribution에 최고로 잘 맞는 variational distribution을 최적화 하는 것
*Posterior distribution: Pθ(z|x) z = latent vatiable
-> obsevation이 주어졌을 때, 관심있는 random variable의 확률분포
-> 사실상 구하는 것이 거의 불가능 에 가까울 때가 많음
-> P(x|z)는 대게 likelihood라고 불림
*Variational distribution(qΦ(z|x))
-> Posterior을 찾는 가장 근사한 값을 만들어 내는 분포
-> Loss function을 최소화하는 것이 필요(KL divergence와 True posterior사이에서)
- 하지만 targer을 모르는데 어떻게 찾아 나갈 것인가?
-> ELBO trick을 사용해보자.
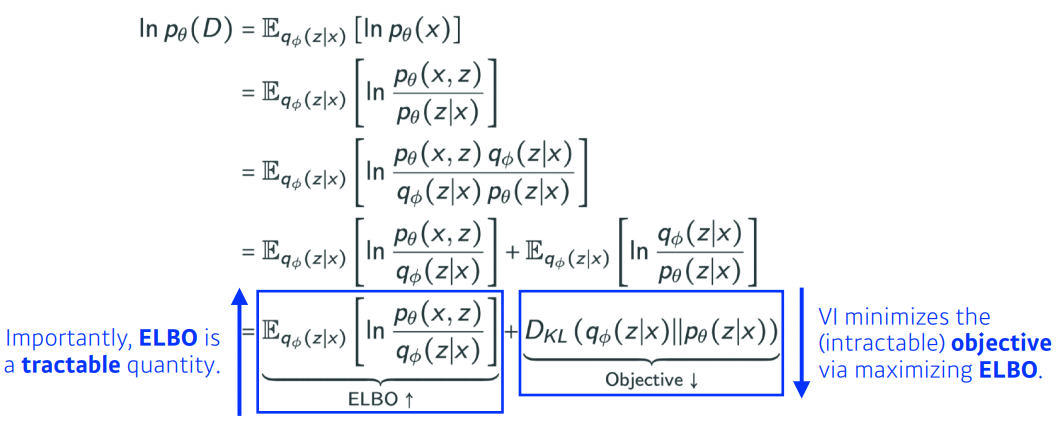
- ELBO를 가져와 보게되면 Reconstruction Term과 Prior Fitting Term으로 나누어 진다.
-> Reconstruction Term: 엄밀한 의ㅣ로는 inexplicit model으로 auto-encoder의 loss function을 말함.
-> Prior Fitting Term: 점들의 분포가 사전분포와 비슷하게 만드는 것.

- 한계점
-> 가능도 계산이 어려움(Intractable model)
-> Prior Fitting Term은 반드시 미분(Differentiable)가능 해야한다. -> diverse latent prior distribuions를 사용하기 어려움
-> 대부분의 경우 isotropic gaussian을 사용함(Prior distribution으로)
- Adversarial Auto-encoder이 개발됨 - variational Auto-encoder에 있는 prior fitting term을 GAN objective로 변경
🔥 GAN(Generative Adversarial Network)

- Generator와 Distriminator가 같이 성능을 향상시킴으로 학습이 됨(min/max게임)
- VAE와 비교하면 아래 그림과 같다.

- Discriminator의 경우 최적화는 다음 식과 같다.

- Generator의 경우 최적화는 다음 식과 같다.

🔥 DCGAN: DNN을 사용하는 것이 좋고 Leaky-ReLU를 사용하면 좋다와 같은 연구 결과를 가져옴
🔥 Info-GAN: GAN의 특정 모듈에 집중하게 해줌.

🔥 Text2Image: 문자가 주어지면 이미지를 생성

🔥 Puzzle-GAN: 이미지의 일부분(Sub patch)를 가지고 복원하는 GAN

🔥 Cycle-GAN: 이미지 사이의 도메인을 바꿔줌. Cycle-consistency loss - GAN구조가 2개

🔥 Star-GAN: 모드를 정해줄 수 있음

🔥 Progressive-GAN: 고차원의 이미지를 만들어 냄, 4x4부터 1024x1024까지 늘려가며 training함


'인공지능' 카테고리의 다른 글
| [Day 17] NLP - RNN & LSTM & GRU (0) | 2021.02.16 |
|---|---|
| [Day 16] NLP - Bag-of-Words & Words Embedding (0) | 2021.02.16 |
| [Day 14] Math for AI - RNN (0) | 2021.02.04 |
| [Day 13] DL Basic - CNN & Computer Vision Applications (0) | 2021.02.03 |
| [Day 12] Math for AI - Convolution (0) | 2021.02.02 |



